线性回归属于回归问题。对于回归问题,解决流程为: 给定数据集中每个样本及其正确答案,选择一个模型函数h(hypothesis,假设),并为h找到适应数据的(未必是全局)最优解,即找出最优解下的h的参数。这里给定的数据集取名叫训练集(Training Set)。不能所有数据都拿来训练,要留一部分验证模型好不好使,这点以后说。先列举几个几个典型的模型:
最基本的单变量线性回归: 形如h(x)=theta0+theta1*x1
多变量线性回归: 形如h(x)=theta0+theta1x1+theta2x2+theta3*x3
多项式回归(Polynomial Regression): 形如h(x)=theta0+theta1x1+theta2(x2^2)+theta3*(x33) 或者h(x)=ttheta0+theta1x1+theta2sqr(x2) 但是我们可以令x2=x22,x3=x3^3,于是又将其转化为了线性回归模型。虽然不能说多项式回归问题属于线性回归问题,但是一般我们就是这么做的。
所以最终通用表达式就是: 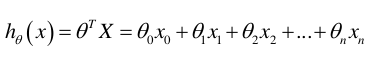 不用在意图片h(x)中间夹的theta字符,只是一个习惯而已,不写theta也可以的。还有我不知道怎么在博客里输入theta那些字符,凑合着看。
不用在意图片h(x)中间夹的theta字符,只是一个习惯而已,不写theta也可以的。还有我不知道怎么在博客里输入theta那些字符,凑合着看。
1.代价函数(Cost Function)
计算建立的模型对真实数据的误差,叫建模误差(Modeling Error)。误差越低,模型对数据拟合度越高。例如给出: m:训练集的样本个数 n:训练集的特征个数(通常每行数据为一个x(0)=1与n个x(i) (i from 1 to n)构成,所以一般都会将x最左侧加一列“1”,变成n+1个特征) x:训练集(可含有任意多个特征,二维矩阵,行数m,列数n+1,即x0=1与原训练集结合) y:训练集对应的正确答案(m维向量,也就是长度为m的一维数组) h(x):我们确定的模型对应的函数(返回m维向量) theta:h的初始参数(常为随机生成。n+1维向量)
得代价函数J(theta): 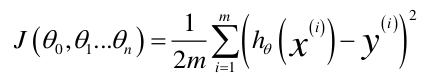 (图中等号左侧的theta0,theta1...thetan以后直接用向量theta表示。)
(图中等号左侧的theta0,theta1...thetan以后直接用向量theta表示。)
有了代价函数,我们的目的就是找到一组参数theta使得代价最小,稍有常识的人就能知道,这个函数肯定是有最小值的,不会出现负无穷下面两个标题就是讲了最小化J(theta)的两个方法。
2.正规方程(Normal Equation)
吴恩达老师这个是放在最后讲的,但是对于中国学生,我觉得其实这个先讲反而更好。 正规方程是针对某些线性回归问题的方案,例如对于我们熟知的 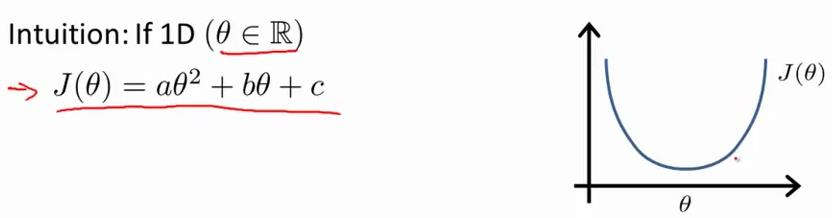 要把上面的代价方程找出theta最小值,本质上就是二次函数嘛。我们直接求导计算导数为0处即为最小值。求解theta轻轻松松一步到位。同样对于多参数的线性回归,只要求偏导即可获得每个theta值到达全局最优解。。 那么现在在矩阵中,假设我们的训练集矩阵为X,“正确答案”为y,则theta可以如上面所说的各自求偏导数直接求出。但是直接这样做非常耗时,因此数学家由此推导出了更好的方法:
要把上面的代价方程找出theta最小值,本质上就是二次函数嘛。我们直接求导计算导数为0处即为最小值。求解theta轻轻松松一步到位。同样对于多参数的线性回归,只要求偏导即可获得每个theta值到达全局最优解。。 那么现在在矩阵中,假设我们的训练集矩阵为X,“正确答案”为y,则theta可以如上面所说的各自求偏导数直接求出。但是直接这样做非常耗时,因此数学家由此推导出了更好的方法: 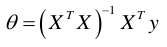 这个公式本质就是从上面求导这一方法推导出来的。推导过程:https://zhuanlan.zhihu.com/p/22474562
这个公式本质就是从上面求导这一方法推导出来的。推导过程:https://zhuanlan.zhihu.com/p/22474562
当然很显然的是,如果矩阵不可逆就不能用这个方案了(出现这个情况的原因可能是1.各个特征不独立、有关联,比如出现了重量和质量两个特征(至少在同一个地方两者完全成比例);2.特征数量大于所给训练集样本个数)。
3.(批量)梯度下降算法((Batch) Gradient Descent)
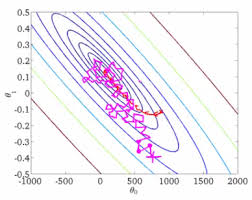
上述方法简单易使用但是局限高,而梯度下降算法使用更广泛更通用。当然这个算法放到现在也有人说它过时了,但还是很有必要学习个。 先定下一组预设参数,通常可以是随机生成的,不断微调h的参数直到达到代价J的局部最小值(Local Minimum)。因此此算法并不一定能找到全局最小值(Global Minimum)。根据初始theta选择的不同可能找到不同局部最小值、导致不同结果。下图很形象的表现了这一点。 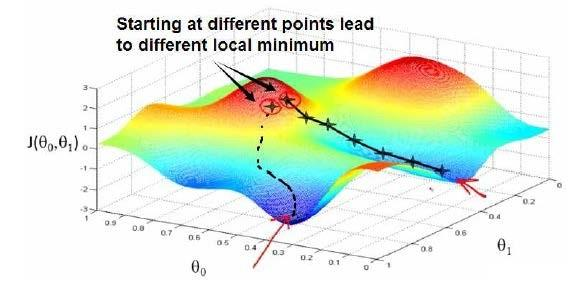
具体实现:我们循环以下算法直到到达局部最小值。 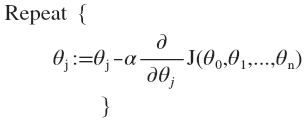
alpha是学习率(Learning Rate),其大小决定了每次循环中theta改变的大小,决定了梯度下降步子迈多大。寻找alpha很关键。alpha小了,每次循环步子也迈的小,要很多步才能到达最低点,速度慢。alpha太大了,可能一下就迈过头了,越过了最低点,并不断一次次越过来越过去就是下不来,太大了甚至可能导致循环无法收敛、甚至发散。
可以看出,随着算法越来越接近局部最小值,J’越小,下降速度越慢,因此alpha只需是个定值,无需在靠近最小值时一起减小alpha。
注意(FBI Warning),每个theta i必须是同步变换,即不能修改了theta1为新计算得的值后再计算要修改的theta2,这样计算出的theta2是基于是修改后的theta1而得到的。因此要计算出全部新theta后统一赋值。
该梯度下降算法有时也被称为批量梯度下降。“批量”指的是在梯度下降的每一步中,我们都用到了所有的训练样本。
线性回归上运用梯度下降
按照梯度下降要求求得代价方程J的导数J’(为了方便书写记J的导数为J’),而对于线性回归模型的J方程上面已经给出,所以将J求导带入,得到: 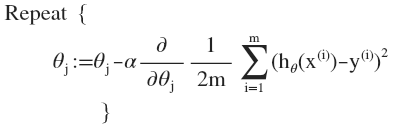
将求导部分求出来,即: 
其中
特征缩放(Feature Scaling)
以房价为例子,现在假设房子价格只受房屋的尺寸(对应theta1)和房间的数量(theta2)影响,房子尺寸的值为 0-2000 平方英尺,而房间数量的值是 0-5,以两个参数为横纵坐标绘图,可以看出图像很扁,梯度下降算法需要非常多次迭代才能收敛。 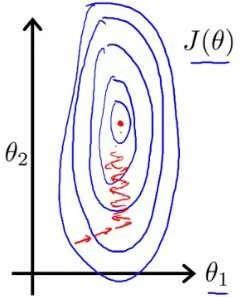
具体为什么会导致迭代很多次,老师的解释是根据图来的,虽然很直观但是根本原因他没说清楚,现在分析下来我认为原因在于,梯度下降时,alpha对于每个参数都是一样的(现在假定alpha为1),则根据最终得到的算法(“Repeat”里面那行),alpha、1/m、h(xi)-y(i)都是一样的,不一样的只有xj(i)(上标下标不会打,凑合着看),那么对于房屋尺寸,尺寸都上千了,数值很大,则theta1的变化也很大,因此对于theta1,alpha太大了,看那张草图,已经导致了越过最小值的情况。而对于theta2呢,房间一共不会超过5,因此对于theta2,alpha太小了,每次就靠近最小值一点点。
这时候我们就需要特征缩放,把所有参数缩放到-1~1的范围,让alpha适应每个参数,每个参数每次的变化都相当。 
具体实施就是令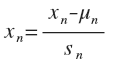 其中u是平均值,s是标准差。把每个数据都如上修改范围,相当于预处理,这样可以对后面线性回归有帮助。而对于多项式回归模型,在运行梯度下降算法前,特征缩放就显得更有必要了。
其中u是平均值,s是标准差。把每个数据都如上修改范围,相当于预处理,这样可以对后面线性回归有帮助。而对于多项式回归模型,在运行梯度下降算法前,特征缩放就显得更有必要了。
其实我个人觉得给每个参数分配一个alpha也是可行的一种方案,不过仔细想想,这样的确实麻烦了点,因为找出合适的alpha不是那么容易的事情。
学习率alpha的选择
上面说到了,alpha太大,步子大了容易扯到蛋,可能导致越过最小值甚至无法收敛;alpha小了又显得娘炮,太慢了。 通常可以考虑尝试这些学习率:α=0.01,0.03,0.1,0.3,1,3,10,多试一试找出比较好的。
局部最优解还是全局最优解
之前也明确说了,梯度下降不一定能获得全局最优解,但是网上那么多教程、博客还是写的很混乱,或者说非常不严谨,都说“到达全局最小值”;包括在吴恩达老师的视频里,也不是描述的很清爽。搞得我很懵。所以问题是,梯度下降用来求最优解,哪些问题可以求得全局最优?哪些问题可能获得局部最优解? 如果函数图像只有一个凹坑,像吴大大视频里的例子全都是一个峰的,那梯度下降最终求得的肯定是全局最优解,应该说获得的局部最优解就是全局最优解。然而对于有多个凹坑的问题,梯度下降获得的局部最优解很有可能的最终结果不是全局最优。对于线性回归问题这也是一样的,网上看到有人说线性回归问题只有一个全局最小值没有局部最小值,感觉这不对,我记得吴恩达老师有说过线性回归也可以有极小值存在的。先mark,等我验证后更新。 但是正规方程呢?当有多个极小值时他一定会返回最小值吗?这点我也不清楚,但是按照周志华老师的机器学习的书上说,当特征数量大于所给训练集样本个数时使用正规方程,会得到多个解,而具体返回哪个解就看算法的选择了。
4.正规方程、梯度下降的选择、比较
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 α | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量 n 大时也能较好适用 | 需要计算(X.T X)^-1。如果特征数量 n 较大则运算代价大,因为矩阵逆的计算时间复杂度为 O(n 3 ),通常来说当 n 小于 10000 时还是可以接受的 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数 θ 的替代方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。 随着我们要讲的学习算法越来越复杂,例如,当我们讲到分类算法,像逻辑回归算法,我们会看到, 实际上对于那些算法,并不能使用标准方程法。对于那些更复杂的学习算法,我们将不得不仍然使用梯度下降法。因此,梯度下降法是一个非常有用的算法,可以用在有大量特征变量的线性回归问题。或者我们以后在课程中,会讲到的一些其他的算法,因为标准方程法不适合或者不能用在它们上。但对于这个特定的线性回归模型,标准方程法是一个比梯度下降法更快的替代算法。所以,根据具体的问题,以及你的特征变量的数量,这两种算法都是值得学习的。
补充:
5.随机梯度下降算法(Stochastic Gradient Descent)
普通的梯度下降算法更新一次theta需要载入所有样本,也就是说一次更新的计算量为m*n^2(m为样本数量,n为参数数量)。这样如果m 非常大,我们需要把所有样本都载入,才能更新一次参数theta,更新一次theta的时间太久了。 而随机梯度下降算法是每次只取一个样本,马上就更新theta。 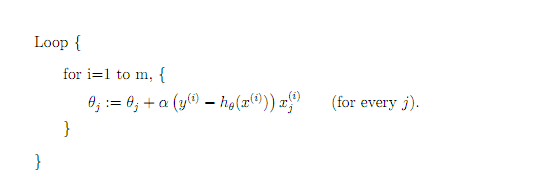 也就是说,每次更新theta的计算量为n^2,当m很大的时候,随机梯度下降迭代一次的速度要远高于梯度下降。 当然有弊有利,利就是更新速度很快,弊就是梯度下降的方向不稳。虽然大致方向上还是向着最低点的,但是一路上都在来回移动。要知道毕竟一套参数不能完全满足所有样本,而每个样本都试图将参数向自己方向靠。(说起来这样不应该很可能没法收敛吗?最后会不会一直在最优解附近游荡。)
也就是说,每次更新theta的计算量为n^2,当m很大的时候,随机梯度下降迭代一次的速度要远高于梯度下降。 当然有弊有利,利就是更新速度很快,弊就是梯度下降的方向不稳。虽然大致方向上还是向着最低点的,但是一路上都在来回移动。要知道毕竟一套参数不能完全满足所有样本,而每个样本都试图将参数向自己方向靠。(说起来这样不应该很可能没法收敛吗?最后会不会一直在最优解附近游荡。)