Mini-batch 梯度下降
将 \(X = [x^{(1)}, x^{(2)}, x^{(3)}, ..., x^{(m)}]\) 矩阵所有 \(m\) 个样本划分为 \(t\) 个子训练集, 每个子训练集称为 \(x^{\{i\}}\), 每个子训练集内样本个数均相同(若每个子训练集有1000个样本, 则 \(x^{\{1\}} = [x^{(1)}, x^{(2)}, ..., x^{(1000)}]\), 维度 \((n_x,1000)\)). 若m不能被子训练集样本数整除, 则最后一个子训练集样本可以小于其他子训练集样本数. \(Y\) 亦然.
训练时, 每次迭代仅对一个子训练集进行梯度下降:
\[ \begin{aligned} & \text{Repeat} :\\ & \qquad \text{For } i = 1, 2, ..., t: \\ & \qquad \qquad \text{Forward Prop On } X^{\{i\}} \\ & \qquad \qquad \text{Compute Cost } J^{\{i\}} \\ & \qquad \qquad \text{Back Prop using } X^{\{i\}}, Y^{\{i\}}\\ & \qquad \qquad \text{Update } w, b \end{aligned} \]
使用 batch 梯度下降法时, 每次迭代都遍历整个训练集, 预期每次迭代成本都会下降, 但若使用 mini-batch 梯度下降法, 若对成本函数作图, 并不是每次迭代都下降, 噪声较大, 但整体上走势还是朝下的.
若样本集较小(小于2000), 无需使用 mini-batch; 否则一般的 mini-batch 大小为 64~512, 通常为 2 的整数次方.
指数加权平均数(Exponentially Weighted Averages)
不是个具体的优化方法, 但是是下面的优化方法的数学基础. 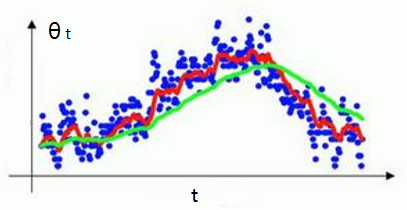
\[ v_t = \beta v_{t-1} + (1 - \beta)\theta_t, \qquad \beta \isin[0,1) \]
\(\beta\) 越大, 画得曲线越平滑, 但画得图像会更为偏右.
为了让加权平均数运算更准确, 我们还需要偏差修正(Bias Correction). 由于我们默认 \(v_0 = 0\), 因此当t较小时, \(v_t\) 会比 \(\theta_t\) 小很多. 为解决这一问题, 得到更准确的估测, 我们不使用 \(v_t\), 而使用 \(\frac{v_t}{1-\beta^t}\).
动量梯度下降法(Gradient Descent With Momentum)
当你的成本函数图像不够圆润, 例如是个很扁的椭圆, 使得梯度下降在y轴很快而在x轴很慢, 此时增加学习率也不是,减少学习率也不是. 动量梯度下降法使用指数加权平均数:
\[ \begin{aligned} v_{dW} & = \beta v_{dW} + (1 - \beta)dW \\ v_{db} & = \beta v_{db} + (1 - \beta)db \\ W & = W - \alpha v_{dW} \\ b & = b - \alpha v_{db} \end{aligned} \]
以此减缓梯度下降摆动幅度.
RMSprop
同 Momentum, 能够很好的消除摆动.
\[ \begin{aligned} S_{dW} & = \beta S_{dW} + (1 - \beta)(dW)^2 \\ S_{db} & = \beta S_{db} + (1 - \beta)(db)^2 \\ W & = W - \alpha \frac{dW}{\sqrt{S_{dW}}} \\ b & = b - \alpha \frac{db}{\sqrt{S_{db}}} \end{aligned} \]
Adam 优化算法
RMSprop 与 Adam 是少有的经受住人们考验的两种算法.
Adam 的本质就是将 Momentum 和 RMSprop 结合在一起. 使用该算法首先需要初始化:
\[ v_{dW} = 0, S_{dW} = 0, v_{db} = 0, S_{db} = 0. \]
在第t次迭代中,梯度下降后:
\[ \begin{aligned} v_{dW} & = \beta_1 v_{dW} + (1 - \beta_1)dW \\ v_{db} & = \beta_1 v_{db} + (1 - \beta_1)db \\ S_{dW} & = \beta_2 S_{dW} + (1 - \beta_2)(dW)^2 \\ S_{db} & = \beta_2 S_{db} + (1 - \beta_2)(db)^2 \\ v_{dW}^{\text{corrected}} & = \frac{v_{dW}}{1-\beta_1^t}, \quad v_{db}^{\text{corrected}} = \frac{v_{db}}{1-\beta_1^t} \\ S_{dW}^{\text{corrected}} & = \frac{S_{dW}}{1-\beta_2^t}, \quad S_{db}^{\text{corrected}} = \frac{S_{db}}{1-\beta_2^t} \\ W & = W - \alpha\frac{v_{dW}^{\text{corrected}}}{\sqrt{S_{dW}^{\text{corrected}}}+\varepsilon} \\ b & = b - \alpha\frac{v_{db}^{\text{corrected}}}{\sqrt{S_{db}^{\text{corrected}}}+\varepsilon} \end{aligned} \]
最后两个式子的 \(+ \varepsilon\) 是为了防止分母为0, 上面 RMSprop 的分母实践中一般也加上, \(\varepsilon\) 通常取 \(10^{-8}\).
Adam 算法结合了 Momentum 和 RMSprop 梯度下降法, 并且是一种极其常用的学习算法, 被证明能有效适用于不同神经网络. 适用于广泛的结构.
学习率衰减(Learning Rate Decay)
如果使用固定的学习率 \(\alpha\), 在使用 mini-batch 时在最后的迭代过程中会有噪音, 不会精确收敛, 最终一直在附近摆动. 因此我们希望在训练后期 \(\alpha\) 不断减小.
以下为几个常见的方法:
法一:
\[ \alpha = \frac{1}{1+decay\_rate*\text{epoch\_num}} \alpha_0 \]
其中 \(\alpha_0\) 为初始学习率; \(\text{epoch\_num}\) 为当前迭代的代数; \(decay\_rate\) 是衰减率, 一个需要调整的超参数.
法二:
\[ \alpha = 0.95^{\text{epoch\_num}} \alpha_0 \]
其中 0.95 自然也能是一些其他的小于 1 的数字.
法三:
\[ \alpha = \frac{k}{\sqrt{\text{epoch\_num}}} \alpha_0 \]
法四:
离散下降(discrete stair cease), 过一阵子学习率减半, 过一会又减半.
法五:
手动衰减, 感觉慢了就调快点, 感觉快了就调慢点.
局部最优问题(Local Optima)
人们经常担心算法困在局部最优点, 而事实上算法更经常被困在鞍点, 尤其是在高维空间中. 成熟的优化算法如 Adam 算法,能够加快速度,让你尽早往下走出平稳段.