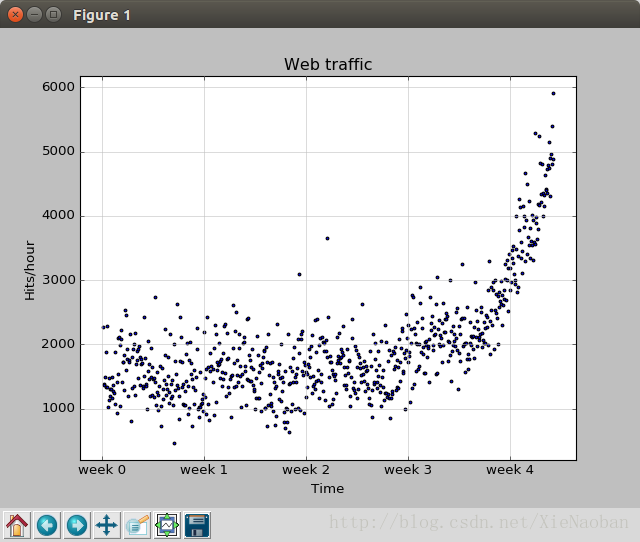
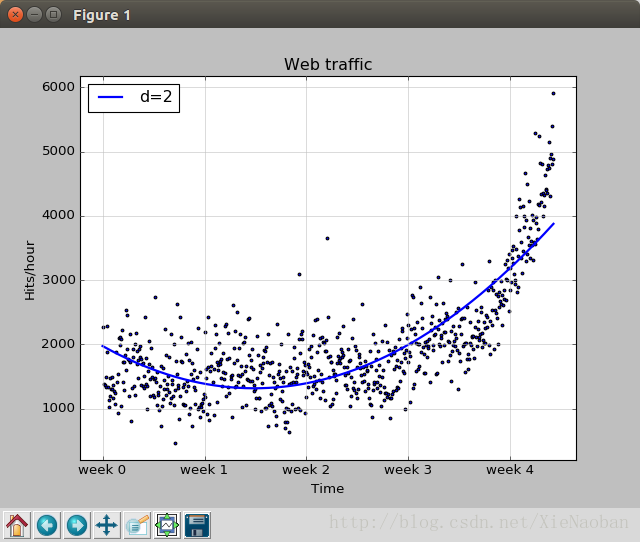
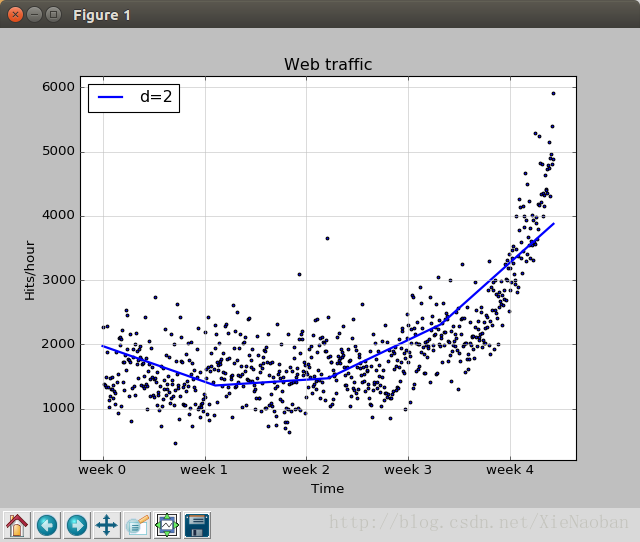
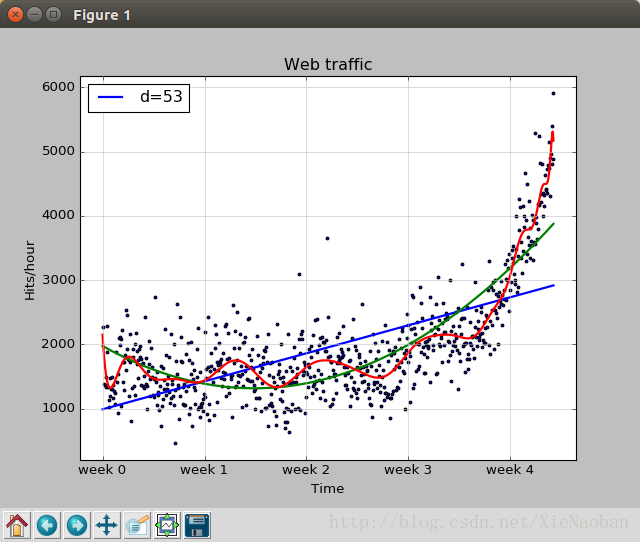
data = sp.genfromtxt("web_traffic.tsv",delimiter="\t") x = data[:,0] y = data[:,1] x = x[~sp.isnan(y)] y = y[~sp.isnan(y)]
然后我们想可视化这些数据,以图表给出,那就用到matplotlib了:
1 2 3 4 5 6 7 8
plt.scatter(x, y, s=6) # 在图标上产生散点,s代表绘制的点的粗细 plt.title("Web traffic") # 标题 plt.xlabel("Time") # x轴标签 plt.ylabel("Hits/hour") # y轴标签 plt.xticks([w*7*24for w in range(10)], ["week %i" % w for w in range(10)]) # 更改x轴的默认刻度显示,以一星期为一个刻度,range中数字10表示x刻度最多显示到第10周 plt.autoscale(tight=True) plt.grid(True,linestyle='-',color='0.75')
import scipy as sp import matplotlib.pyplot as plt
data = sp.genfromtxt("web_traffic.tsv",delimiter="\t") x = data[:,0] y = data[:,1] x = x[~sp.isnan(y)] y = y[~sp.isnan(y)]
plt.scatter(x, y, s=6) plt.title("Web traffic") plt.xlabel("Time") plt.ylabel("Hits/hour") plt.xticks([w*7*24for w in range(10)], ["week %i" % w for w in range(10)]) plt.autoscale(tight=True) plt.grid(True,linestyle='-',color='0.75')